
회사에서 업무를 하며 동료의 좋은 아이디어로 id 채번 방식을 개선 했던 내용을 정리 해보고자 한다.
1. 소개
pk(ID)를 채번하기위해서는 3가지정도의 방법이 필요하다. 그 방법은 다음과 같다.
- DB 의 auto_increment 사용
- redis 채번
- 티켓서버
- UUID
- 트위터 스노우 플레이크
- DB 의 auto_increment
가장 쉽게 생각 가능한 방법인 DB 의 auto_increment를 활용하는 방법이다.
redis 채번 메모리 db 인 redis를 이용해서 순차적으로 채번을 하는 방식이다. 순차적으로 순번을 발급 받을수 있고, 빠른속도로 id 를 채번 가능하지만 redis 가 죽는다면 키의 유실으로 장애로 이어 질수 있다.
티켓서버
티켓 서버는 유일성이 보장되는 ID를 만들어내는 방법중 하나이다. 이 방법은 순차적으로 ID를 발급하는 기능을 가진 서버를 중앙 집중형으로 사용하는것이다. 구현이 간단하고 쉽게 ID를 발급 받을 수 있지만, 티켓 서버 자체가 SPOF(Single Point Of Failur)가 발생하면 해당서버를 사용하는 모든 시스템이 장애로 이어 질 수 있다.
- UUID
ID의 특징이 중복 되지 않는 조건만 생각 한다면 UUID 도 나쁜 선택이 아니다. 하지만 UUID 는 총 128 비트로 길고 ID 를 시간순으로 정렬하기에 어려운 점이 있다.
- 트위터 스노우 플레이크 ID (Twitter Snowflake ID)
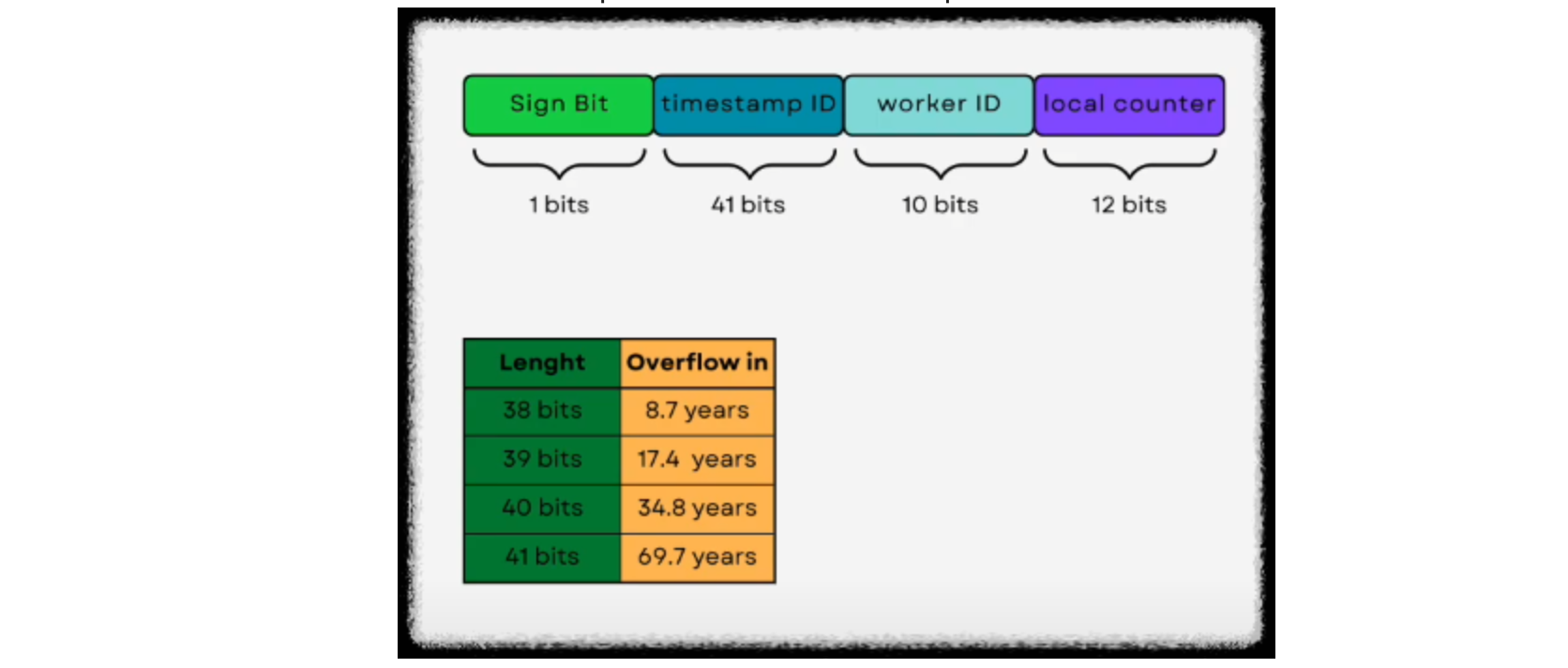
UUID 보다는 조금더 간결하게 64비트를 사용한다. SignBit, TimeStamp,Worker id, localCounter 으로 구성되어있다.
- 타임스탬프 (Timestamp): 41비트
- 41비트로는 현재 시간을 밀리초 단위로 표현합니다.
- 1970년 1월 1일부터 현재까지의 밀리초 단위의 시간을 나타냅니다.
- 타임스탬프는 특정 시간 이후에 생성된 ID가 항상 이전에 생성된 ID보다 크도록 하는 역할을 합니다.
- 머신 ID (Machine ID): 10비트
- 분산 시스템에서 여러 머신이 동일한 시간에 ID를 생성할 경우, 각 머신을 구분하기 위해 사용됩니다.
- 시퀀스 번호 (Sequence Number): 12비트
- 같은 머신에서 동일한 밀리초 내에 생성된 ID를 구분하기 위해 사용됩니다.
트위터 스노우 플레이크를 사용하면 64 비트만 사용가는 하게 되고 이는 pk를 Long (Numeric)타입으로 사용할수 있는 장점이 있다.
Numeric 한 타입으로 사용하면 어떤 장접이 있을까?
- 성능 : 메모리가 적고 문자열보다 비교가 더 빠르다.
- 표쥰화 : 텍스트 인코딩, 대소문자 구분, 공백등 문자열 키에서 발생하는 문제가 사라진다.